Ok, there’s a good chance you’re reading this because A) you saw it on twitter or B) you’ve been racking your brain for the past few days wondering what the hell is going on with your AKS Cluster.
We rolled out a deployment last week and we noticed that all was not well. What wasn’t well? First, our xdbcollection pod wouldn’t start up. Looking at the logs, it was pretty…unhelpful.
[LOGMONITOR] ERROR: Failed to start entrypoint process. Error: 216That’s it. I went to describe the pod, and it simply said “BackOff” and “restarting failed container” which again…was not very helpful. To make matters MORE annoying, I noticed that two of my CD pods (there are ten) were failing to startup for the same reason. But the other eight? They didn’t have a problem. When I looked in k9s at my cluster, it was pretty ugly:
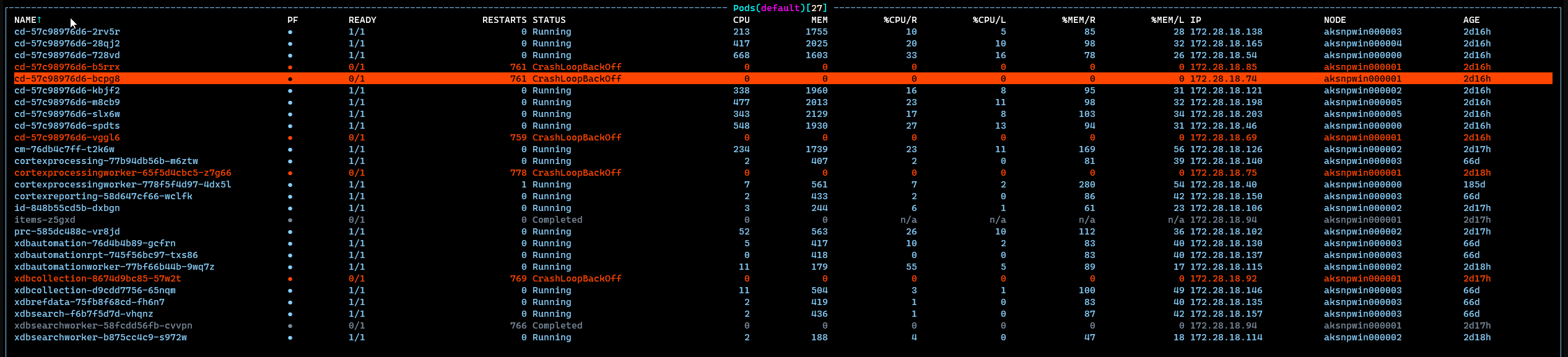
Some things worked, some things didn’t work. It didn’t have much rhyme or reason, either…at first. But there’s a happy ending here. (yay!). How did I get there? Let’s roll down the rabbit hole:
First, I noticed that the error code was coming from log monitor. What if that Error 216 is a ProcessMonitor code? Maybe some insight there. I hopped over the source code for LogMonitor and found where the error message was getting generated. Here’s the code:
if (!bSuccess)
{
exitcode = GetLastError();
logWriter.TraceError(
Utility::FormatString(L"Failed to start entrypoint process. Error: %lu", exitcode).c_str()
);
}Ok, so that’s not super helpful. But, it ruled out that LogMonitor was at fault. I know that GetLastError() is a system function that just bubbles up whatever exploded last. So let’s look at what the error codes actually mean. Here’s some basic documentation, because you know…light reading.
ERROR_EXE_MACHINE_TYPE_MISMATCH 216 (0xD8) This version of %1 is not compatible with the version of Windows you're running.
So this was my face:

If you google that status code (ERROR_EXE_MACHINE_TYPE_MISMATCH) you see a whole lot of “Well that doesn’t seem relevant anymore for my life” errors. Things like 32-bit vs 64-bit. Or things like having Windows ME crap the bed on you. Or driver issues. But nothing k8s related…not anywhere close. This is the point that things were less fun than normal. Here I am, pods failing, and the trying to digest errors related to an old OS. That’s like going to a mechanic with an engine noise and walking out with a rubber chicken. Not good.
After looking at that pod listing screen for the 15th time in a day or so…it occurred to me that all the failed pods were on the same Node. But that shouldn’t matter, should it? It looks like it does. Let’s look deeper. In Azure, you could see all nodes were healthy. In theory, if the nodes are unhealthy, AKS should try to redeploy them (Via the VMSS) without an issue.
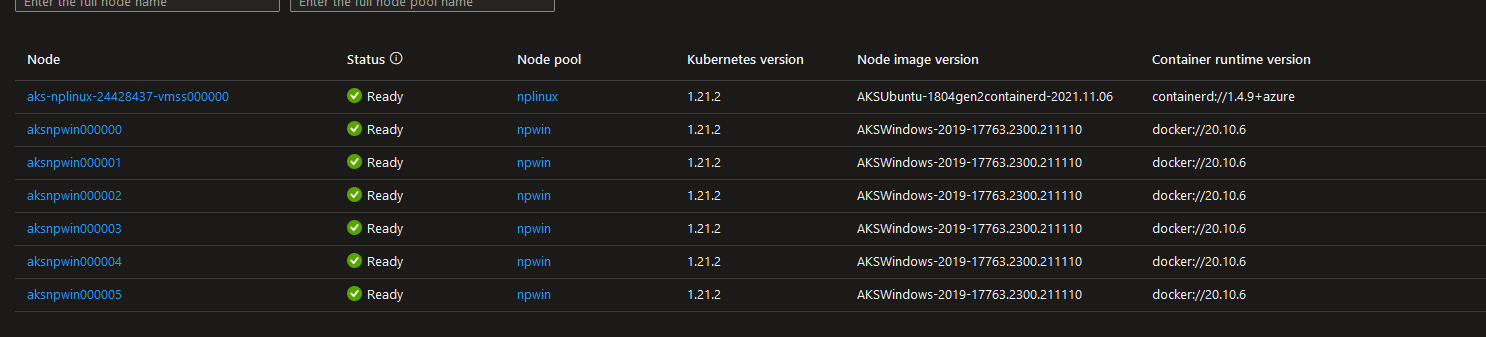
So it doesn’t look like things are going bad at all. Everyone is healthy, AKS versions match, Image versions match…all is well, right? Wrong.
If I hopped into Node 0, I see this:

All looks like you’d expect it to. Pods up and running, ready, maybe some questionable restart counts on the OMS Agent, but all in all…we’re good. Now let’s hop into Node 1, which looked to be sporting some grumpy pods:
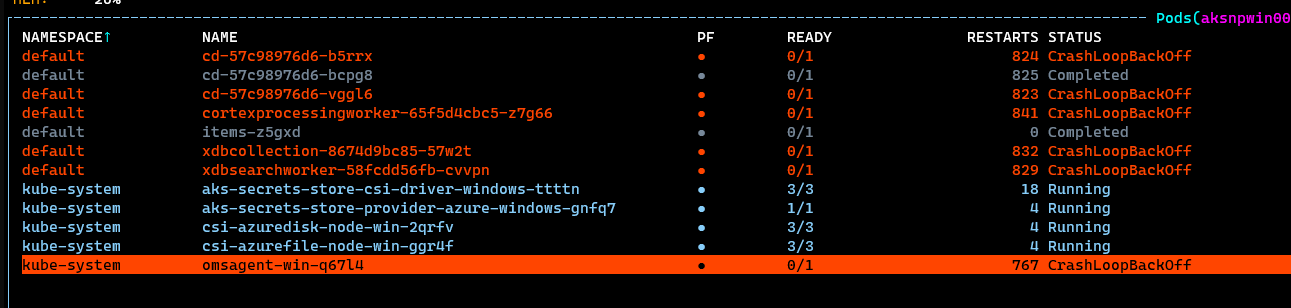
One thing which was interesting was the omsagent-win pod was not happy. This made me feel that the issue here was nothing related to Sitecore, but was in-fact related to AKS itself. Delving into that OSM Agent pod, we saw the same issue as the others:

Something was wrong with the entire node, not just our code. We hopped over to the Virtual Machine Scale Set which was running the node and restarted it. After a few minutes, the pods started popping up and entering the Running phase, which was a nice change. This seems to have solved the issue.

My only theory is that during our deployment, something at the OS level broke. That’s a little bit of a scary statement, honestly. One of the major selling points for AKS is to not have to think about the OS. If this had not been production and preventing a rollout, I would have for sure opened a ticket.
Again, I hope this never happens to you. It was truly a frustrating few days to try and figure out what was going on. If you are here, I hope this helped you!
TL;DR: A node broke. We restarted it. Getting to that knowledge was a PITA.