UPDATE: I totally forgot to put the source code link in here! https://github.com/RAhnemann/Container-Warmer
If you’ve been around the docker block a little bit with Sitecore, you know by now that when a container is launched, it’s not really ready to do anything. It’s barely alive. In fact, Docker and k8s know this, and have a solve! In Docker Compose, you’ll see lines like this:
healthcheck:
test: ["CMD", "powershell", "-command", "C:/Healthchecks/Healthcheck.ps1"]
timeout: 300sIn the k8s world, you have this:
livenessProbe:
httpGet:
path: /healthz/live
port: 80
httpHeaders:
- name: X-Kubernetes-Probe
value: Liveness
timeoutSeconds: 300
periodSeconds: 30
failureThreshold: 3
startupProbe:
httpGet:
path: /healthz/ready
port: 80
httpHeaders:
- name: X-Kubernetes-Probe
value: StartupThey both look really different, but do essentially the same thing. In that Healthcheck.ps1, it calls those “healthz” endpoints. But what do those actually do?
The “live” endpoint really does just that. If it can return a page with a 200 status code, the container is up. It’s breathing. It’s not ready to run a marathon, but it’s there.
The “ready” endpoint only does a little bit more. It makes sure it can connect to SQL, and it can connect to xConnect services. Those are important, but we all know if we were to swap a slot on an App Service to bring a new deployment live without anything else, we’re going to be in for a bad day. What about Item Caches and HTML Caches? Sure we can do a little bit with the pre-fetch cache, but that’s not enough (and it hasn’t been…ever).
So what are you to do?

Ok, so we need something more. Something like an HTTP Request that fetches some pages for us that should preload some of the HTML cache. That’s not too hard, is it? Turns out, it’s really not. You could technically just have a page that loads all the URLs you want and executes the HTTPS Requests and then returns a 200 status code. I’m hoping for something a little less rigid though. Something with flexibility, should we need to change things up in the future. Whose to say we’ll only ever need to warm up pages? What if there’s custom APIs we need to load? You probably see where I’m going here:
We need a pipeline. Sitecore does these really well, so why not do that? Ok, it’s settled. First, we’re going to create a controller and a method:
public class HealthzController : ApiController
{
[HttpGet]
public HttpResponseMessage Warm(bool verbose = false)
{
var args = new WarmupArgs();
try
{
CorePipeline.Run("warmup", args);
}
catch (Exception e)
{
args.IsFailed = true;
args.Messages.Add("Error Running Pipeline: " + e.Message);
}
HttpResponseMessage msg;
if (args.IsFailed)
{
msg = verbose ? Request.CreateResponse(HttpStatusCode.InternalServerError, args.Messages) : Request.CreateErrorResponse(HttpStatusCode.InternalServerError, "Error in Warmup");
msg.Headers.Pragma.ParseAdd("no-cache");
msg.Content.Headers.TryAddWithoutValidation("Expires", "0");
return msg;
}
else
{
msg = verbose ? Request.CreateResponse(HttpStatusCode.OK, args.Messages) : Request.CreateResponse(HttpStatusCode.OK, "Healthy");
msg.Headers.Pragma.ParseAdd("no-cache");
msg.Content.Headers.TryAddWithoutValidation("Expires", "0");
return msg;
}
}
}You were probably expecting a bit more elaborate. Well, it’s not really. You essentially want to invoke a pipeline, see the results and either write them back (using verbose) or not. That’s it. The rest of the code below line 10 is just formatting a response. So what’s our processor look like that’s plugged in here?
It’s also pretty slim:
//If we've already failed, why are we still going?
if (args.IsFailed)
return;
try
{
foreach (var url in _urls)
{
//Create the full URL from the base and path specified
var fullUrl = $"{_baseUrl}{url}";
try
{
//If we've got this in cache, no need to go further
if (_allowCaching && IsCached(fullUrl))
{
Log.Info($"Warmup: Cached Url '{fullUrl}'", this);
args.Messages.Add($"Success. Url Warmup: '{fullUrl}' (from cache)");
continue;
}
Log.Info($"Warmup: Loading Url '{fullUrl}'", this);
//Retrieve the url using the specified agent string (for debugging)
using (var client = new WebClient())
{
client.Headers.Add(HttpRequestHeader.UserAgent, "container-warmer");
client.DownloadString(fullUrl);
}
args.Messages.Add($"Success. Url Warmup: '{fullUrl}'");
//Finally add it to the cache
if (_allowCaching)
{
AddToCache(fullUrl);
}
}
catch (WebException wex)
{
//Pages move and change. A 404 should not cause the warmup to fail. Just move along.
if (wex.Status == WebExceptionStatus.ProtocolError)
{
if (wex.Response is HttpWebResponse errorResponse &&
errorResponse.StatusCode == HttpStatusCode.NotFound)
{
Log.Error($"Warmup: 404. General Web Exception: {wex.Message}", wex, this);
args.Messages.Add($"Skipped (404). Url Warmup: '{fullUrl}'");
if (_allowCaching)
{
AddToCache(fullUrl);
}
}
else
{
Log.Error($"Warmup: Non 404 response. {wex.Message}", wex, this);
}
}
else
{
//Something else has happened. This may be more significant
Log.Error($"Warmup: General Web Exception: {wex.Message}", wex, this);
args.IsFailed = true;
args.Messages.Add($"Failed. Url Warmup: '{fullUrl}': {wex.Message}");
}
}
catch (Exception ex)
{
Log.Error($"Warmup: Unhandled Error fetching page: {fullUrl}", ex, this);
args.IsFailed = true;
args.Messages.Add($"Failed:General. Url Warmup: '{fullUrl}'");
}
}
}
catch (Exception ex)
{
args.IsFailed = true;
Log.Error("Warmup: FATAL Unhandled Error in UrlProcessor", ex, this);
}Some notable chunks here:
- We have a flexible base url. When we look at the whole processor, we can see how that’s set. (line 10)
- We have the ability to cache. (line 15) (If I am processing 30 URLs and I timeout for some reason on #29, I don’t want to hit 28 before hand. It allows me to speed up a retry process.
- 404s are ok. What if a page is renamed? It happens. I’ll want to update the config later, but I still want to keep going (line 42)
- There’s a short circuit for previous failures. All processors should probably have this (line 2)
Ok, now how do you add this route?
RouteTable.Routes.MapHttpRoute("warmup", "healthz/warm", new { action = "Warm", controller = "Healthz" });I stuck with “healthz” to A) Keep with the Sitecore way of naming and B) avoid collision on content items. I doubt anyone has a page called “Healthz” on their site. 1337.
And now for configuration. How does this all come together? You can probably figure out the init pipelines as well as API registration. But the processors are a bit more flexible:
<warmup>
<processor name="healthcheck" type="ContainerWarmer.Processors.UrlProcessor, ContainerWarmer">
<urls hint="list:IncludeUrl">
<url>/healthz/ready</url>
</urls>
</processor>
<processor name="default" type="ContainerWarmer.Processors.UrlProcessor, ContainerWarmer" role:require="ContentDelivery">
<param desc="allowCaching">true</param>
<urls hint="list:IncludeUrl">
<url>/</url>
</urls>
</processor>
<processor name="default" type="ContainerWarmer.Processors.UrlProcessor, ContainerWarmer" role:require="ContentManagement or Standalone">
<param desc="allowCaching">true</param>
<urls hint="list:IncludeUrl">
<url>/</url>
<url>/sitecore</url>
</urls>
</processor>
</warmup>There’s three processors in there, all of the same type. The first one actually calls the native default healthz/ready check. It’s like a healthz inception!

Essentially, you can load in a list of URLs via the urls node. We can see the usage of the role check for the second two. Our CM instance wants to load the /sitecore path, while the CD doesn’t care about it at all.
Also notice the parameter in there for “allowCaching” which does what we’d expect it to. It allows us to cache the success of hitting that URL. We don’t want this for the healthcheck node! Let it keep going and going.
So you’re good to go now! Right? Wrong.

We need to include this code with our CM/CD builds! Good thing this is out on the public docker hub, and can easily be pulled in with a simple docker pull! Head on over to https://hub.docker.com/r/rahnemann/container-warmer/tags for all the goodness. You’ll want to incorporate this right with all the other layers in your CD docker file:
If you were looking at the Custom Images repo and inside the \docker\build\cd Dockerfile, you’d some modifications like see the following:
# escape=`
ARG BASE_IMAGE
ARG SPE_IMAGE
ARG TOOLING_IMAGE
ARG SOLUTION_IMAGE
ARG WARMUP_IMAGE
FROM ${TOOLING_IMAGE} as tooling
FROM ${SOLUTION_IMAGE} as solution
FROM ${WARMUP_IMAGE} AS warmup
FROM ${BASE_IMAGE}
SHELL ["powershell", "-Command", "$ErrorActionPreference = 'Stop'; $ProgressPreference = 'SilentlyContinue';"]
# Copy development tools and entrypoint
COPY --from=tooling \tools\ \tools\
COPY --from=solution \modules\ \modules\
WORKDIR C:\inetpub\wwwroot
# Add SPE module
COPY --from=solution \website .\
COPY --from=warmup \website .\
#Need to give ourselves a chance to loopback for local warmup
ENTRYPOINT ["C:\\LogMonitor\\LogMonitor.exe", "powershell", "C:\\tools\\scripts\\entry-shim.ps1"]Emphasis is on lines 7, 11, and 25. This works just like another module where you’re layering it into your images. Nothing *too* complicated here.
Ok, that’s a lie. Line 28 is something you don’t typically see. So play out this scenario with me… We want to warm up our new pod. We access the site over HTTPS, it goes out to the public DNS and then it comes back into AKS. It’s going to hit what pod? Our pod that hasn’t passed the ready check? Nope, it’s going to hit the already-running pods out there. That’s not going to help us much, is it? No. No it won’t. We need to somehow force traffic back to the pod that’s doing the warming. Good thing this is a standard windows OS. We can poke the hosts file with a quick and easy entry that ensures traffic goes back to this pod only. This isn’t hard. The timing of it is hard. We need this to happen when the pod is created, so we need our own entrypoint that does the work for us before we’re even trying to create HTTP requests.
Enter in our entry-shim.ps1
Write-Host "Creating Loopback for [$env:LOOPBACK_HOSTS]"
"127.0.0.1 $env:LOOPBACK_HOSTS" | Out-File C:\windows\system32\drivers\etc\hosts
Write-Host "Starting W3SVC"
& "C:\\Run-W3SVCService.ps1"This is a shim for a reason. It does one thing (write the hosts file) and then calls the base entrypoint of the Run-W3SVCService.ps1. The above code uses an environment variable to control what’s written. Super helpful if you’re going to do this on a per-environment basis. Simply pass this into your k8s file from your pipeline or through key-vault and you’re good to go. You can see this in action here if you look at the logs for your pod:
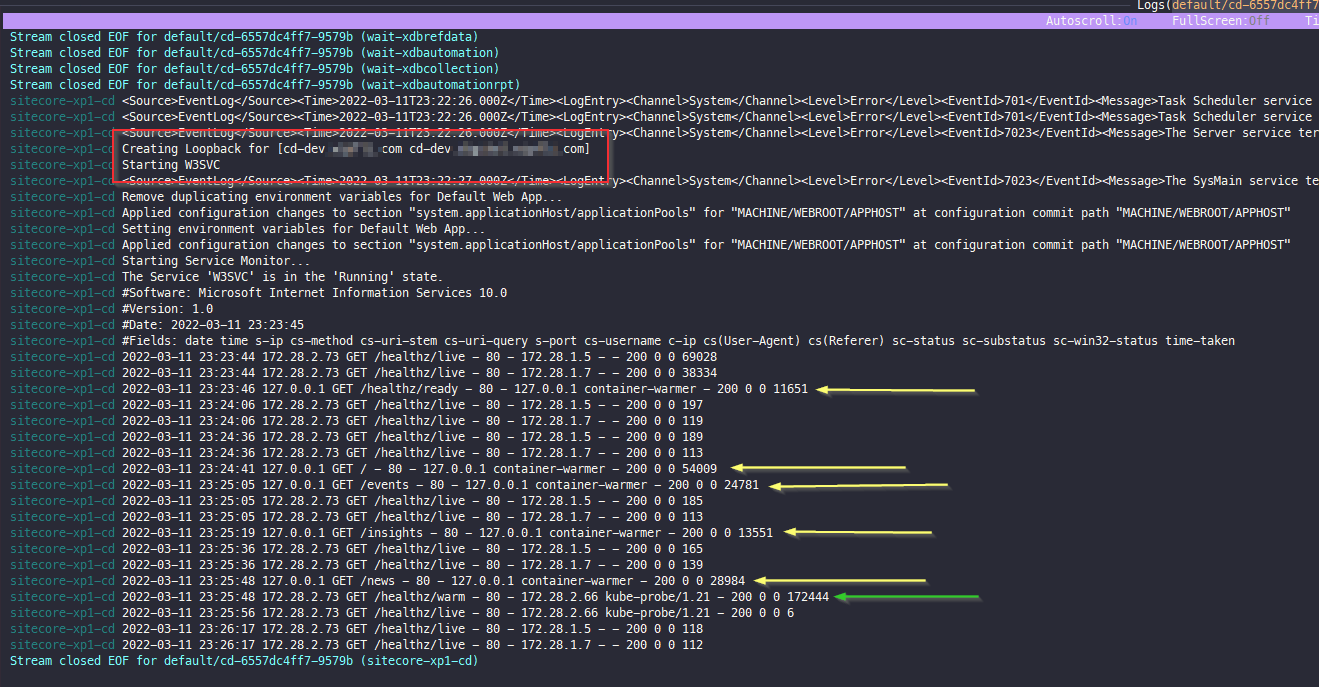
The first thing pointed out is the red box. This is our hosts file entries being added. Next, you’ll see all the URLs being hit via the warmup processor (the “container-warmer” agent is a goo indicator”) on the yellow arrows and finally you see the k8s probe hitting the “healthz/warm” url by the green arrow. Why does this happen last, and not first? Simple: It doesn’t complete its request until all the other URLs have been hit. Once it is done going through the loop or URLs, it completes.
The final thing to do is to update your k8s file to replace the “/healthz/ready” probe with “/healthz/warm“. You can do that manually or you can use some neat kustomize patches to do that. Those are going to be covered in a later post.
This was a bit more complicated than I had hoped it would be, but it’s really the right way to go, I believe. And it’s using some best practices for k8s and docker. Hope this helps you out! Thanks for sticking with me!

That’s really useful, though a bit more fiddly than it initially appears.
Your pipeline processor – where do AddToCache() and IsCached() come from? And which cache do they refer to?
Thanks!
Gosh… I totally neglected to put the link to the repo in here. That’s updated! Here’s the link to the processor: https://github.com/RAhnemann/Container-Warmer/blob/main/Processors/UrlProcessor.cs You can see the methods in there. It’s just an Application Cache. It shouldn’t need to be manipulated by Sitecore, so I opted for simpler. Hope this helps!
Hi There,
We have implemented your container warmer with our Sitecore environment. We are grabbing your image from the docker repo. We are successfully calling the warmup function, but when it goes to hit the URL we are getting “ERROR Warmup: General Web Exception: Unable to connect to the remote server”. We have updated the CD pods hosts file and we have updated the base URL to be our dev URL. Any ideas?
If you were to remote into the pod, can you curl to the dev url? If not, try an ‘ipconfig /flushdns’ as writing to the hosts file didn’t seem to update the OS (we had to do this for some instances).
We came to the same conclusion and it is now working for us as well! Thank you. One other question though, when we look at our CD logs the warmup process appears to be working but we only ever see a log for the last URL in our list. See below log for example. Any ideas why or where we could look to verify that all the other URLs are being warmed up correctly?
2023-08-03 17:28:59 127.0.0.1 GET /Accounts/Billing/Your-Power-Bill/How-to-Read-Your-Bill – 80 – 127.0.0.1 container-warmer – 200 0 0 43939
2023-08-03 17:28:59 127.0.0.1 GET /Accounts/Billing/Your-Power-Bill/How-to-Read-Your-Bill – 80 – 127.0.0.1 container-warmer – 200 0 64 269341
2023-08-03 17:28:59 127.0.0.1 GET /Accounts/Billing/Your-Power-Bill/How-to-Read-Your-Bill – 80 – 127.0.0.1 container-warmer – 200 0 64 266536
2023-08-03 17:28:59 127.0.0.1 GET /Accounts/Billing/Your-Power-Bill/How-to-Read-Your-Bill – 80 – 127.0.0.1 container-warmer – 200 0 64 163907
I’ll say the only time it’s hit the same URL over and over is if it can’t reach it or something else along those lines. It’s pretty good about moving to the next when you get a success (200)