A standard part of every website is the Sitemap XML. Traditionally, the CM instance (XM Cloud included) generates this XML file (or files) and stores it in the media library and publishes to Edge it with each publish. Your headless application pulls this from Edge and streams it out to the browser. That’s pretty simple and it works, yeah? Yeah! But, say you need to do something custom with your Sitemap.xml. Like, you want things in buckets to be collapsed. Or you want to resolve certain sub-pages in locations where they don’t actually sit (canonical exists for a reason, yeah?). Well, you’d change your Sitemap Crawler in .NET, or you’d add in another processor. But wait….you aren’t supposed to touch CM in XM Cloud.

Can we do meet these requirements and NOT break this cardinal rule of XM Cloud development? Yep. Buckle up, this post has some meat to it.

The foundation of this module is a rather simple GraphQL query. This simply takes in a site name and language to return a list of routes. See below.
query sitemap(
$siteName: String!
$language: String = "en"
$pageSize: Int = 100
$after: String = ""
) {
site {
siteInfo(site: $siteName) {
routes(language: $language, first: $pageSize, after: $after) {
total
pageInfo {
endCursor
hasNext
}
results {
route {
path
template {
name
}
updated: field(name: "__Updated") {
value
}
url {
path
}
... on _Sitemap {
changeFrequency {
...enumVal
}
}
}
}
}
}
}
}
fragment enumVal on LookupField {
targetItem {
field(name: "value") {
value
}
}
}I’ve added a few fields to this, namely the template and the time it was last updated. We’ll need those later! Here’s what a result set looks like:
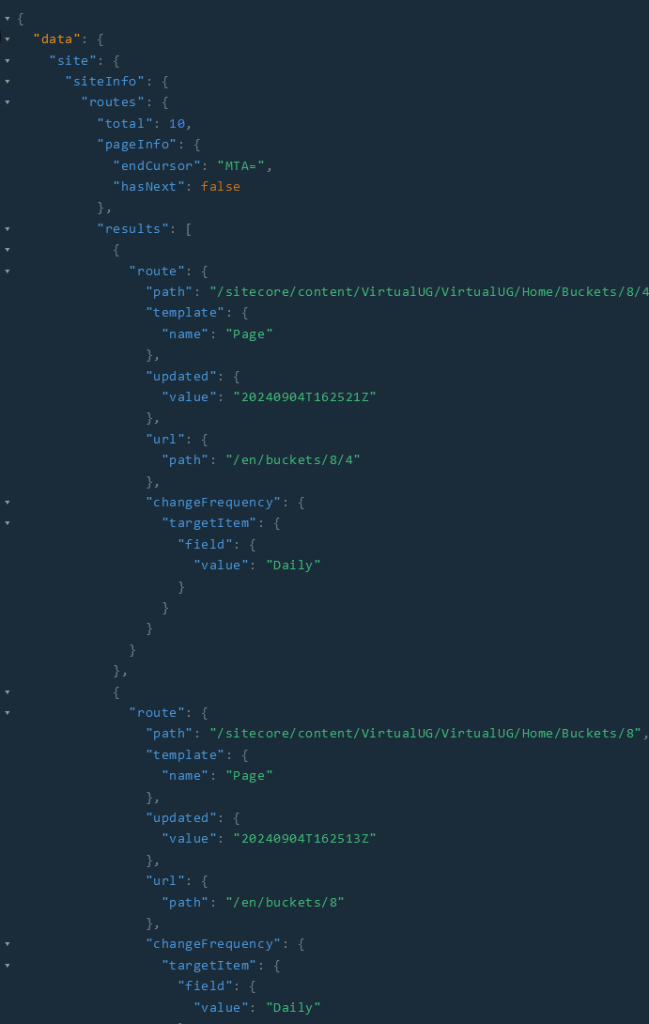
Pretty minimal…but again, we’re making a sitemap here, not a whole webpage. One thing that’s maybe not intuitive is the path. Why do we care about that? Simply put, we’re going to sort using that. Everyone loves having the homepage as the first item in their Sitemap XML. Why? Maybe…actually I don’t know why. But they do. So it’s there.

Now that we have the graph query knocked out, we need to wrap that in a service! I borrowed and trimmed some logic from an existing service (because why reinvent the wheel) and created a graphql-sitemapxml-service.ts. The main method in here I wanted to detail out is getAllSitemapItems, which returns a SitemapData. SitemapData is just a fancy dictionary, which is pretty versatile:
export interface SitemapData {
[itemid: string]: SitemapItem[];
}
export interface SitemapItem {
itemPath: string;
path: string;
lastModified: Date;
template: string;
language: string;
final: {
url: string;
//Whether or not we should continue to process this item
shouldProcess: boolean;
};
}Take note of the “final” object there. That final contains the url which is rendered as well as a flag on whether or not the item should process. (e.g. once you process an item, don’t process it again).
public async getAllSitemapItems(languages: string[]): Promise<SitemapData> {
const rawData: SitemapData = {};
//Can't use a map() here as it's not async safe
for (const lang of languages) {
rawData[lang] = [];
rawData[lang] = await this.getSitemapItems(lang);
}
//Last thing to do is to make it a dictionary of item, not of languages
const finalSitemapData = this.invertSitemapToItems(rawData);
return finalSitemapData;
}We iterate over all languages and then use that graph query to add them to that dictionary. Our dictionary starts off based on language-to-items, but them we invert it to path-to-items. When we process a sitemap item later, it’s going to be way simpler iterate. The rest of the service code is simple plumbing. Nothing out of the ordinary.

Once we’ve retrieved the data from the service, this is where the magic happens. I’ve created a plugin which will set the final URL of the SitemapItem. Out of the box, the default plugin will just update the final:url to the value from path:url. This plugin system is where you should be modifying the sitemap generation behavior. I’ve also included a bucket processor as a second example. It checks the template name of the item and does some slicing and dicing. See below:
import { SitemapData, SitemapXmlPlugin } from '..';
class BucketSitemapXmlPlugin implements SitemapXmlPlugin {
order = 1;
process(data: SitemapData): SitemapData {
for (const itemPath in data) {
data[itemPath].map((item) => {
if (item.template == 'Bucket Page' && item.final.shouldProcess) {
const segments = item.path.split('/');
//If our url is /buckets/a/b/page we want to remove the second and third segments
if (segments.length >= 4) {
segments.splice(segments.length - 3, 2);
item.final.url = segments.join('/');
item.final.shouldProcess = false;
}
}
});
}
return data;
}
}
export const bucketSitemapxmlPlugin = new BucketSitemapXmlPlugin();Compare that to the default:
import { SitemapData, SitemapXmlPlugin } from '..';
class DefaultSitemapXmlPlugin implements SitemapXmlPlugin {
//It's the default, make it go last
order = 9999;
process(data: SitemapData): SitemapData {
for (const itemPath in data) {
data[itemPath]
?.filter((item) => item.final.shouldProcess)
.forEach((item) => {
item.final.url = item.path;
item.final.shouldProcess = false;
});
}
return data;
}
}
export const defaultSitemapxmlPlugin = new DefaultSitemapXmlPlugin();Programming note: Since we’re using the same plugin architecture as the rest of the solution, we need to add this to the generate-plugins.ts. It’ll look something like this:
{
distPath: 'src/temp/sitemapxml-plugins.ts',
rootPath: 'src/lib/sitemap-xml/plugins',
moduleType: ModuleType.ESM,
},And the execution of that plugin? EZ-PZ. Sort the plugins, and call each process method.
export default async function processSitemap(
data: SitemapData,
config: SitemapConfiguration
): Promise<SitemapData> {
debug.sitemapxml('processSitemap start');
const start = Date.now();
//Process all plugins
(Object.values(plugins) as SitemapXmlPlugin[])
.sort((p1, p2) => p1.order - p2.order)
.forEach((p) => p.process(data, config));
debug.sitemapxml('processSitemap in %dms', Date.now() - start);
return data;
}Now that we’ve correctly set the content of the final:url, it’s time to render the actual XML. The main issue we need to avoid is rendering too many URLs in a single sitemap. Google has a hard cap here and could end up ignoring some of your items. The logic in this section gets a bit nuts, so let’s outline our possible cases:
- Our sitemap has no limit on the number of items in it, or it has less items than max items specified.
- We have more items than the max items specified.
- We are requesting /sitemap.xml. We now need to render a sitemapindex instead of a sitemap.
- We are requesting /sitemap-XX.xml. We now need to render a subset of the items based on the main result set and a paging mechanism.
So what does THAT logic look like in code? Take a look. It’s a little bit much.
if (maxURLsPerSitemap == 0) {
//There is no limit to the pages in the sitemap
if (sitemapCurrentPage == 0) {
//No max per page, render it all
debug.sitemapxml('Default rendering. %d items', sitemapURLCount);
sitemapContents = buildSitemap(processedSitemapURLs, sitemapConfig);
} else {
console.error('Tried to render a sitemap page when paging was disabled');
//We aren't paging our sitemap, but we requested a page...
return res.redirect('/404');
}
} else {
//We have a limit on the number of pages we can render in a sitemap!
if (sitemapURLCount > maxURLsPerSitemap) {
const sitemapPageCount =
sitemapURLCount % maxURLsPerSitemap == 0
? sitemapURLCount / maxURLsPerSitemap
: sitemapURLCount / maxURLsPerSitemap + 1;
if (sitemapCurrentPage == 0 && sitemapPageCount > 0) {
//We're not looking for a specific page, show the index
debug.sitemapxml('Generating Sitemap Index for %d pages', sitemapPageCount);
sitemapContents = buildSitemapIndex(sitemapPageCount, sitemapConfig['hostname']);
} else if (sitemapCurrentPage > 0 && sitemapCurrentPage <= sitemapPageCount) {
//We're looking for a specific page, and it's valid
let start = (sitemapCurrentPage - 1) * maxURLsPerSitemap - 1;
if (start < 0) start = 0;
const selectSitemapURls = Object.fromEntries(
Object.entries(processedSitemapURLs).slice(start, start + maxURLsPerSitemap)
);
sitemapContents = buildSitemap(selectSitemapURls, sitemapConfig);
} else if (sitemapCurrentPage > 0 && sitemapCurrentPage > sitemapPageCount) {
//We're looking for a specific page, and it's outside the count of pages we have
console.error(
`Tried to retrieve an invalid page number: ${sitemapCurrentPage}. Max pages: ${sitemapPageCount}.`
);
return res.redirect('/404');
}
}
}The juicy parts here lie on
- Line 8 – Build normal Sitemap
- Line 27 – Build SitemapIndex
- Line 38 – Build subset
This might be the trickiest part to digest, hence the superior comments 🙂

Ok, at this point, we’re onto the actual generation of the Sitemap (or SitemapIndex) XML. There’s two functions to accomplish this. One for the index:
const buildSitemapIndex = (pages: number, hostName: string): string => {
const opening = '<sitemapindex xmlns="http://sitemaps.org/schemas/sitemap/0.9" encoding="UTF-8">',
closing = '</sitemapindex>';
let sitemaps = '';
for (let page = 1; page <= pages; page++) {
sitemaps += `<sitemap><loc>https://${hostName}/sitemap-${String(page).padStart(
2,
'0'
)}.xml</loc></sitemap>`;
}
return opening + sitemaps + closing;
};And one for a Sitemap:
const buildSitemap = (pages: SitemapData, config: SitemapConfiguration): string => {
const opening = `<?xml version="1.0" encoding="UTF-8"?><urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"${
config['include_alternate_links']?.toLowerCase() == 'true'
? ' xmlns:xhtml="http://www.w3.org/1999/xhtml"'
: ''
}>`,
closing = '</urlset>';
let sitemapPagesContent = '';
for (const pageId in pages) {
config['languages'].split('|').forEach((language) => {
//Find the page instance
const page = pages[pageId].find((p) => p.language == language);
if (page) {
sitemapPagesContent += `<url><loc>https://${config['hostname']}${
page?.final.url
}</loc><lastmod>${page?.lastModified.toISOString().split('T')[0]}</lastmod>`;
//If we need alternate links, we'll iterate through all language except the current
if (config['include_alternate_links']?.toLowerCase() == 'true') {
const altPages = pages[pageId].filter((p) => p.language != language);
altPages.map((p) => {
let langDisplay = p.language;
if (p.language.length === 5 && config['href_lang_mode'] !== 'language-and-region') {
if (config['href_lang_mode'] === 'language-only')
langDisplay = p.language.substring(0, 2);
if (config['href_lang_mode'] === 'region-only')
langDisplay = p.language.substring(3, 5);
}
sitemapPagesContent += `<xhtml:link rel="alternate" hreflang="${langDisplay}" href="https://${config['hostname']}${p.final.url}" />`;
});
//Including the x-default alternate adds in an item based off the default language
if (config['include_x_default'] == 'true') {
const defaultPage = pages[pageId].find((p) => p.language == config['default_language']);
if (defaultPage) {
sitemapPagesContent += `<xhtml:link rel="alternate" hreflang="x-default" href="https://${config['hostname']}${defaultPage.final.url}" />`;
}
}
}
sitemapPagesContent += '</url>';
}
});
}
return opening + sitemapPagesContent + closing;
};A couple quick programming notes on this buildSitemap function:
- You don’t see a priority or changeFreq element. Google doesn’t use them. Nobody does. They’re all a lie. Seriously, go read this.
- We’re only rendering out a subset of languages. Why? Sometimes authors stage content and publish it without it wanting to be crawled. Our sitemap should respect those wishes.
- Alternate Links are just the page in another language version. We do need to basically double-loop her. One loop starts with first language in our languages set, and then renders alternates. Then each alternate renders and loops again. If you have two items that have three languages each, you’re going end up with six total items. Don’t hate me. Hate the system.
- X-Default – This concept applies to multilingual sitemaps. Essentially it allows emphasis on a version of content.
A few closing remarks here:
- You can add debug statements in here just like normal JSS debugging. I’ve used patch-package here and added a custom debugger for sitemapxml
- As with the normal Sitemap XML processor, there’s a risk things could get published between requests. That’s low-risk though as this fetch process is pretty quick to run.
- Configuration is handled via environment variables. See the Config Table below. Any setting in your environment must start with “sitemapxml_” followed by the setting name. For example, setting the default language would lead to “sitemapxml_default_langauge” being set to “en”. As a bonus, any environment setting you prefix with “sitemapxml_” will be added to your configuration object, which is passed into each plugin
- This targets JSS 22.0. It was the latest release when I started. Updating to a later version shouldn’t be a challenge, but you’ll want to test it out, including the patch-package settings.
| Setting Name (case insensitive) | Description |
| hostname | The hostname to prepend to all URLS. Note: If no value is set, the incoming hostname will be used. Note: Do not include https. We’re all on https. Seriously. Example: “www.rockpapersitecore.com” |
| languages | Determines which languages to include in the site. Note: Separate each language with a pipe Example: “en|en-ca|fr-ca” |
| default_language | Used to set the x-default hreflang language. Must be a single language. |
| include_alternate_links | Determines whether or not to render alternate links for each language version of the item Values other than “true” are considered “false” |
| include_x_default | Determines whether or not to include the x-default alternate language Values other than “true” are considered “false” |
| href_lang_mode | Determines how to render hreflang values Valid values: “language-only”, “region-only” or “language-and-region” Default: “language-and-region” |
So what did we to today:
- Fetch our Routes from Edge and sort them by path
- Run them through a set of processor plugins
- Write the XML out to the browser
- Relax at night, knowing everything we did today doesn’t drop a line of code onto your CM Server
The entire code is up on github. This only contains the files you need to run and can be unzipped right on top of your existing JSS 22.0.0 solution: https://github.com/RAhnemann/XM-Cloud-Headless-Sitemap
I realize this was a beefy one, but I had a bunch of fun creating it!

Edit: It was pointed out that we need do one last thing! We want to turn off the CM generation of the sitemap. Why do that when we’re doing it in the head? Check out the docs here: https://doc.sitecore.com/xmc/en/developers/xm-cloud/configure-a-sitemap.html for details on how to accomplish this!